What running an AI team actually looks like
I built a multi-agent AI team with five LLM agents and ran it for a week. Here's what I learned about AI leadership, team dynamics, and what the human actually needs to do.
Everyone talks about AI taking our jobs. The conversation rarely gets further than that. No one agrees on what it actually means, and most discussions collapse into speculation before they reach anything useful.
My last two quarters went into adjacent experiments: rebuilding my personal cv using RAG and gamifying it. This quarter I wanted to go further. Understand what agentic AI actually looks like when it's doing work, not just assisting with it.
I decided to simulate the future as people currently imagine it. To take a real product workflow with real roles, real handoffs, real deliverables, and replace humans with agents. Not AI tools that help a human team. An AI team, run like a human one.
This opened up questions I didn't expect to care about as much as I did. How do agents collaborate? What does their agency actually look like under pressure? If their output fails a review, do they learn, and if so, how? And underneath all of it: are we watching very fast pattern matching, or is something more significant happening with agentic AI right now?
I built a multi-agent system that coordinates five LLM agents, each running as a long-lived Claude Code or Codex CLI session: a Product Manager, a Product Designer, a Tech Lead, two Developers, and a Code Reviewer.
The system is the experiment. Whether a single model can write code is solved. The harder question is what happens when you give multiple agents distinct roles and ask them to collaborate through a structured workflow. Does the coordination hold? Do the handoffs lose meaning the way they do on human teams? Does the pipeline produce real output, or just plausible activity?
The orchestration layer matters more than any individual agent. A capable model in a bad workflow produces waste. An average model in a well-designed pipeline produces value. How agents communicate, how work flows between stages, what gets blocked and what gets escalated, that's what determines whether anything useful comes out the other end.
Plenty of people are building agentic AI systems like this. I wanted to build my own, because that's how I've always learned fastest. Not studying from the outside, but operating inside the thing and seeing what breaks.
The team works like this:
- The PM reads a templated doc with high-level requirements, analyzes the codebase, and proposes improvements framed around user need
- The Product Designer reviews user-facing proposals for experience quality, clarity, and trust
- The Tech Lead reviews proposals (with design feedback attached) for technical feasibility, shapes the implementation, and assigns tasks
- The Developers implement approved specs on isolated branches
- The Reviewer checks the code and approves or sends it back
- Myself, the only human on a team of six
The PM routes work based on what kind of proposal it is. User-facing work (product, UX, trust, onboarding, workflow) goes through the Designer first, who adds experience feedback before passing to the Tech Lead. Technical proposals skip straight to the Tech Lead. The pipeline adapts its depth based on what's flowing through it.
They talk through a message pipeline. Each handoff is a typed contract, not a conversation. There's a safety layer that blocks dangerous actions and escalates risky ones for human approval. There's a dashboard so I can watch everything in real time.
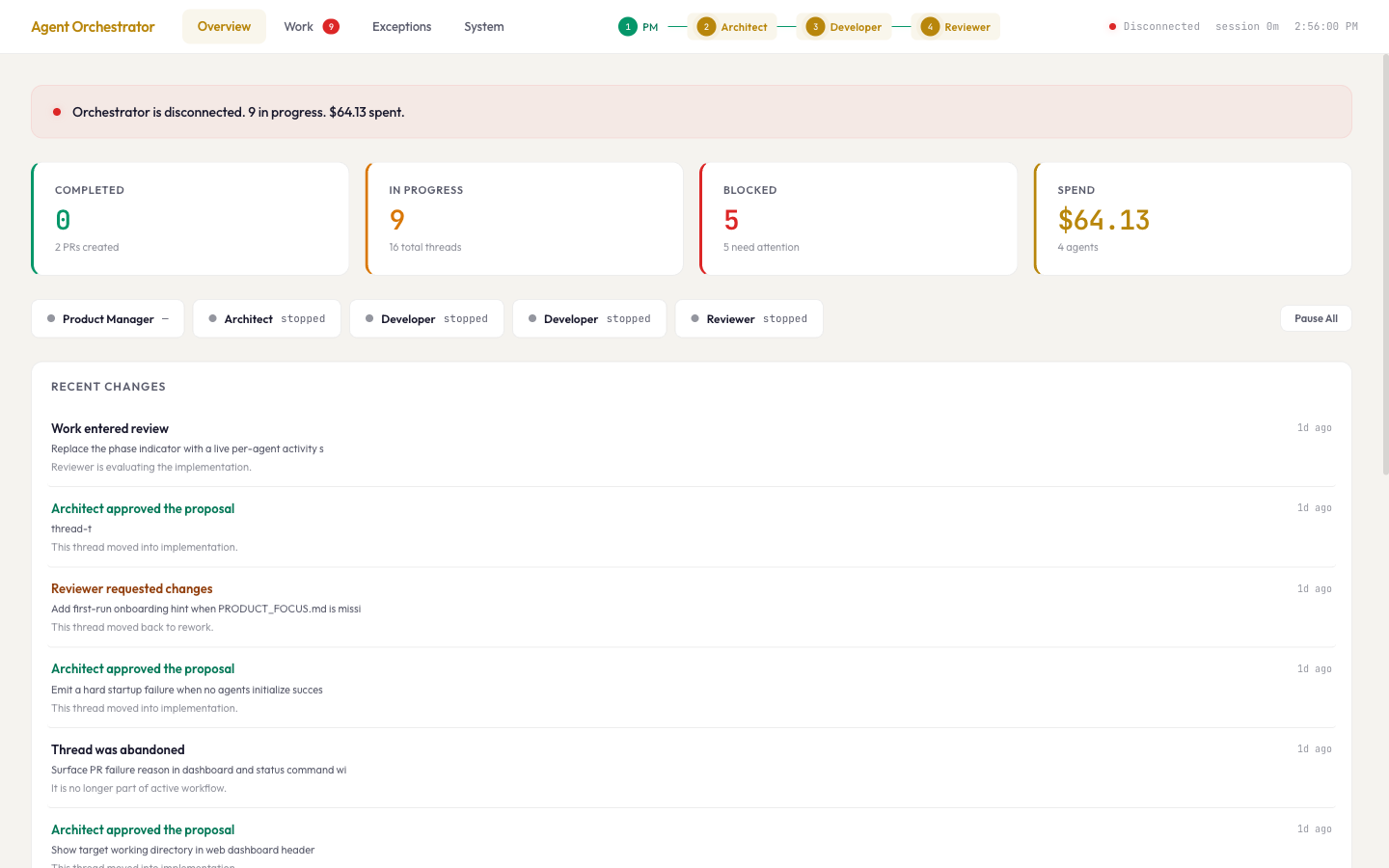
The surprise: it felt exactly like managing a real team
I expected it to feel like configuring software and then agents would sort things out. It didn't. Within hours, dynamics I've seen on every team I've led started showing up. But I couldn't tell at first whether the problems were coming from the agents or from me.
Was the PM drifting because the model was unfocused, or because I hadn't given it clear enough priorities? Were the handoffs failing because agents can't communicate well, or because I'd designed the contracts too loosely? Was the pipeline full of noise because AI generates too much, or because I hadn't built the backpressure to stop it?
The honest answer is that most of the early failures were mine. The agents did exactly what I set them up to do. When the PM produced twelve scattered proposals, that was a reflection of a missing product brief, not a broken model. When handoffs turned into a telephone game, that was a reflection of my decision to let agents pass prose instead of typed contracts. When the review loop ran three times on the same bug, that was the system working correctly. The Developer's capability boundary was real, but the pipeline detected it and stopped.
The dynamics that showed up weren't unique to AI. They're the same dynamics that show up on every team. The difference is that AI teams can't compensate for bad leadership the way human teams can. Humans cover for fuzzy process with judgment, context, and hallway conversations. AI agents execute exactly what you gave them. If the structure is wrong, the output is wrong. Confidently and at speed.
That's what made the week so clarifying. I couldn't blame the team. The team was a mirror.
Left alone, the AI PM generated twelve proposals in its first run. Well-articulated, technically reasonable, covering everything from tests to performance to security. The Tech Lead approved two. Eighty-three percent rejection rate. So I did what I'd do with any team. Wrote a one-page product brief. Three to five priorities. Explicit out-of-scope items. The effect was immediate. Proposals aligned. Approval rate went up. Work started flowing toward real value.
The AI PM responded to product leadership the same way a human PM does. Give it clear priorities and the output gets dramatically better. The skill wasn't AI-specific. It was the same instinct I've been developing my whole career, applied in a new context.
Early on, the agents talked to each other in natural language. Paragraphs of reasoning passed from one role to the next. By the time the Developer got a spec, it had been through multiple layers of translation, the same telephone game every organization knows, except here nobody could ask a clarifying question.
I replaced that prose with minimal typed payloads. Title, priority, acceptance criteria. Decision, blocking issues, specific file and line comments. Less expressive, far more reliable. AI made the case for structured handoffs more clearly than any retrospective ever has.
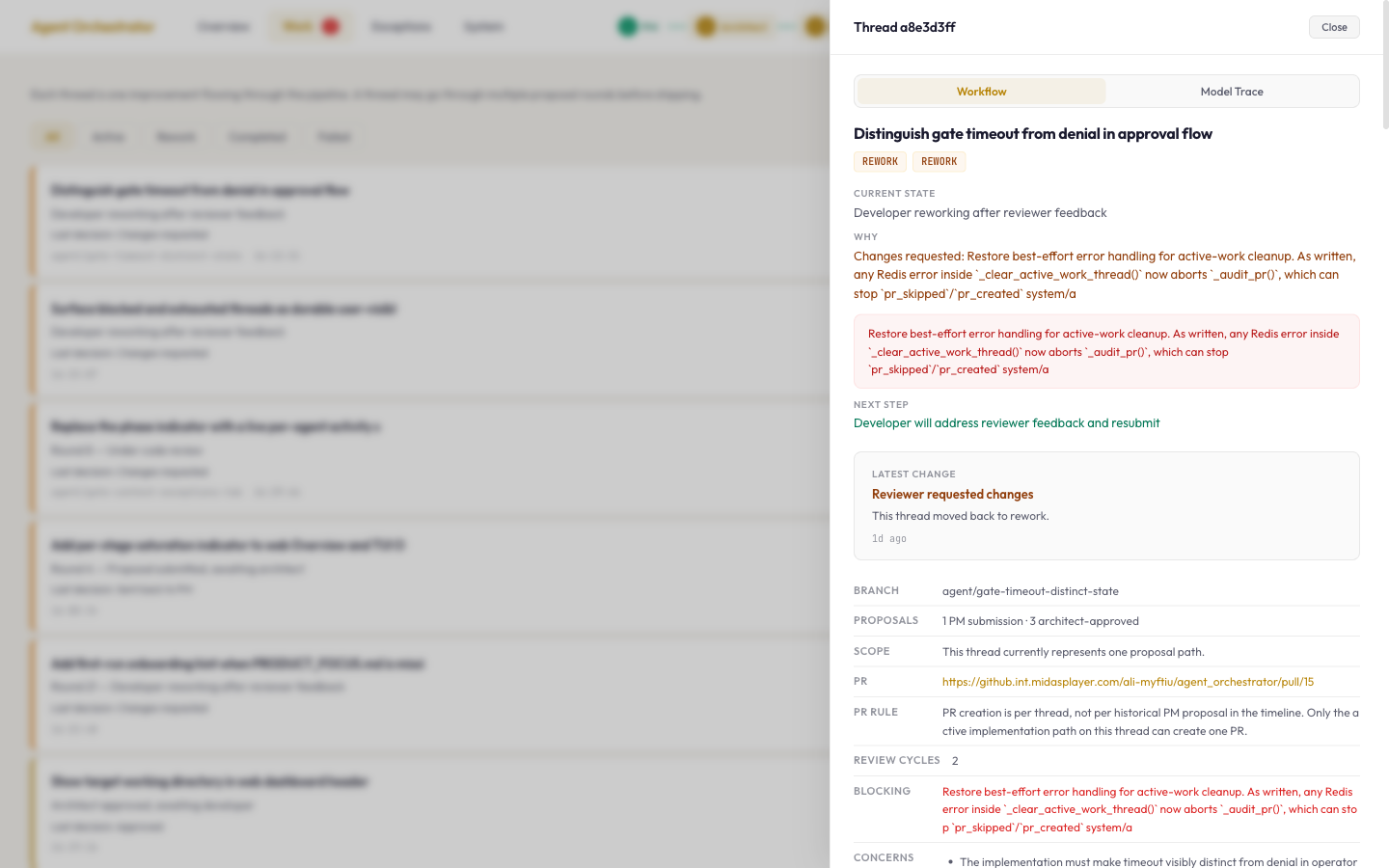
One proposal went through three review cycles. The Developer kept submitting code, the Reviewer kept catching the same bug: a subtle issue with library-specific exception types. After three rounds the system blocked the thread. I've seen this exact loop on human teams. The difference is the system caught it in hours, not sprints.
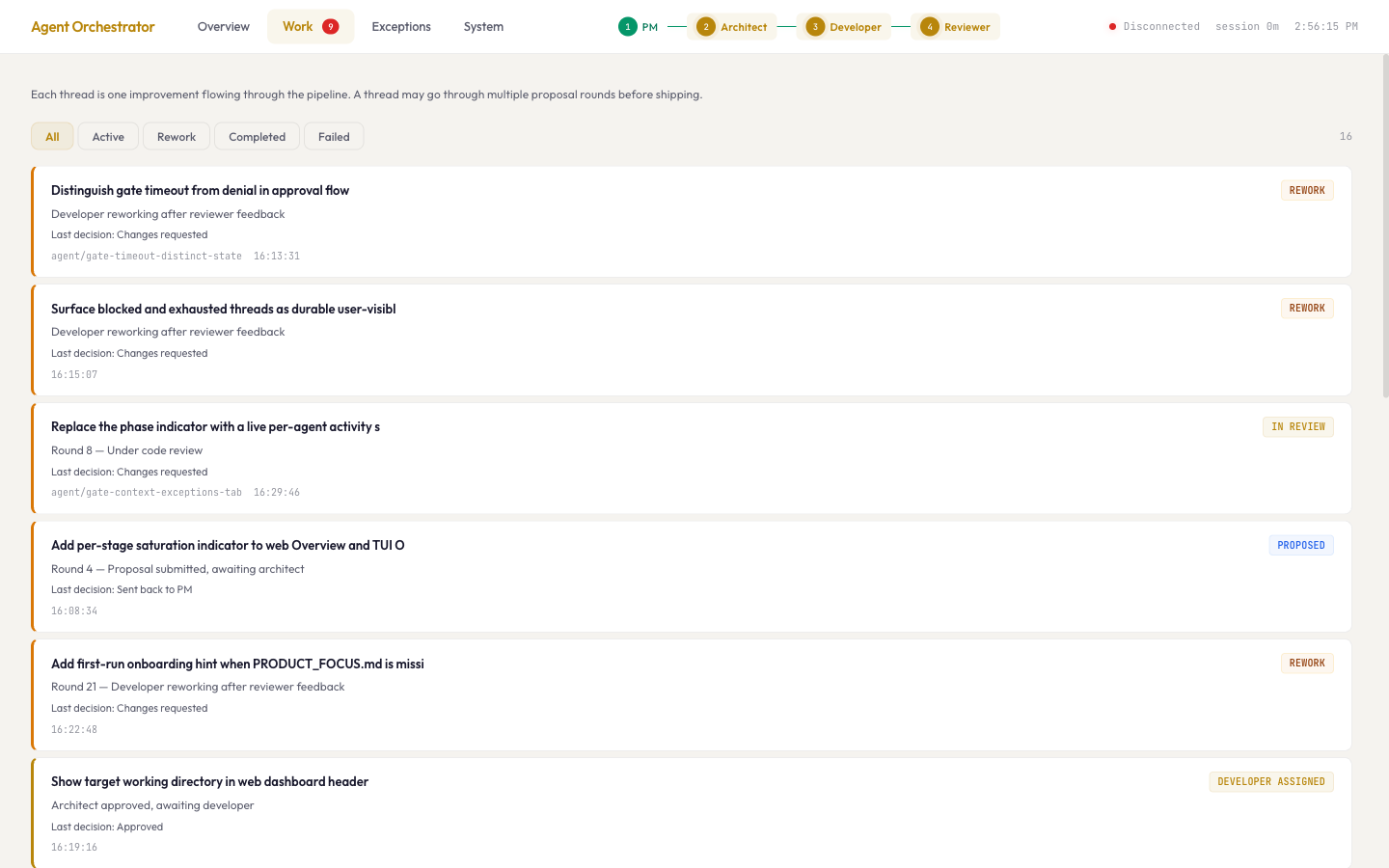
At some point I realized what I was actually doing. Not just running an AI team. Running a controlled experiment on management, stripped of all the human compensation that normally hides these dynamics. Human teams are forgiving enough to cover for fuzzy process. AI teams aren't. The PM drifts without priorities. Handoffs lose context without structure. Activity isn't progress without measurement. WIP limits matter even when the team never gets tired. Every principle I'd learned from managing real teams showed up, except now I could see it clearly because nothing was being smoothed over by social norms.
The twist: it felt nothing like managing a real team
AI teams turn ambiguity into system behavior, not friction. On human teams, ambiguity creates questions and Slack threads. On AI teams, ambiguity creates confidently wrong output. The agents don't ask for clarification. They interpret and continue.
When the workflow state was unclear, the agents didn't work around it. They duplicated work. They looped. They stalled. They filled the pipeline with sophisticated-looking noise. If thread IDs were shared across multiple proposals, the pipeline didn't flag the confusion. It collapsed everything into one untrackable blob.
No informal context. No accumulated team culture. No "everyone knows the Tech Lead cares about error handling." If it's not in the system prompt, it doesn't exist. I found myself writing increasingly specific role definitions, not because the agents were stupid, but because there was no other way to transfer institutional knowledge. My focus became refining the explicit craft for each role: the PM evaluates user need, the Designer evaluates experience quality, the Tech Lead evaluates technical shape. Each one has a written standard for what "good" looks like. On a human team, half of that lives in people's heads.
On a human team, judgment is distributed. The PM has opinions. The tech lead pushes back. The developer raises concerns. Here, I was the only one who could tell whether the work mattered. When the PM drifted toward internal cleanup instead of user-facing improvements, nobody noticed but me. When a thread was stuck on a bug the Developer couldn't fix, no agent flagged it. They just kept trying.
You're the only person in the room with judgment, and you're also the one who built the room. That combination is heavier than it sounds.
Some of that weight is structural. Better tooling will reduce it. I could have built a coach agent that monitors flow, throttles the PM when the pipeline is saturated, flags threads looping without progress. Some of that I did build during the week: the auditor, the pause button, the thread guard that blocks after three failed cycles. Each one took a specific kind of tiredness off my plate.
But the deeper fatigue wasn't operational. It was being the only one who could judge whether the work mattered. No agent can tell you the PM is optimizing for the wrong thing. No dashboard flags that the product direction has quietly drifted. That judgment is upstream of any tooling. Every person running an AI team will feel it. The ones who build good systems will feel it less on the operational side and more on the strategic side. The tooling gets better. The loneliness of judgment doesn't.
I abandoned a stuck thread instead of resetting it for a fourth attempt. Most people learn that "when to stop" skill by wasting weeks on something before admitting it won't work. Here I could see the pattern after three cycles. The system gave me the data to make the call fast. On a human team, the same thing plays out over two sprints before someone escalates.
Other days I paused the PM because the pipeline was full. Other times I flushed stale data because restarting clean was better than debugging noise. The system automates execution. It does not automate judgment about when execution isn't working.
What it actually costs
Something most AI writing glosses over: this costs real money, and the waste is visible. Every proposal costs tokens. Every review costs tokens. Every rejected implementation costs tokens. When the PM generated twelve proposals and ten got rejected, those ten still showed up on the bill. When the Developer failed the same code review three times, each attempt cost money, and the third produced the same wrong answer as the first.
It changed how I thought about flow economics. Don't start work the pipeline can't finish. Stop generating proposals when existing ones haven't been reviewed. The gate has to come before the spend, not after.
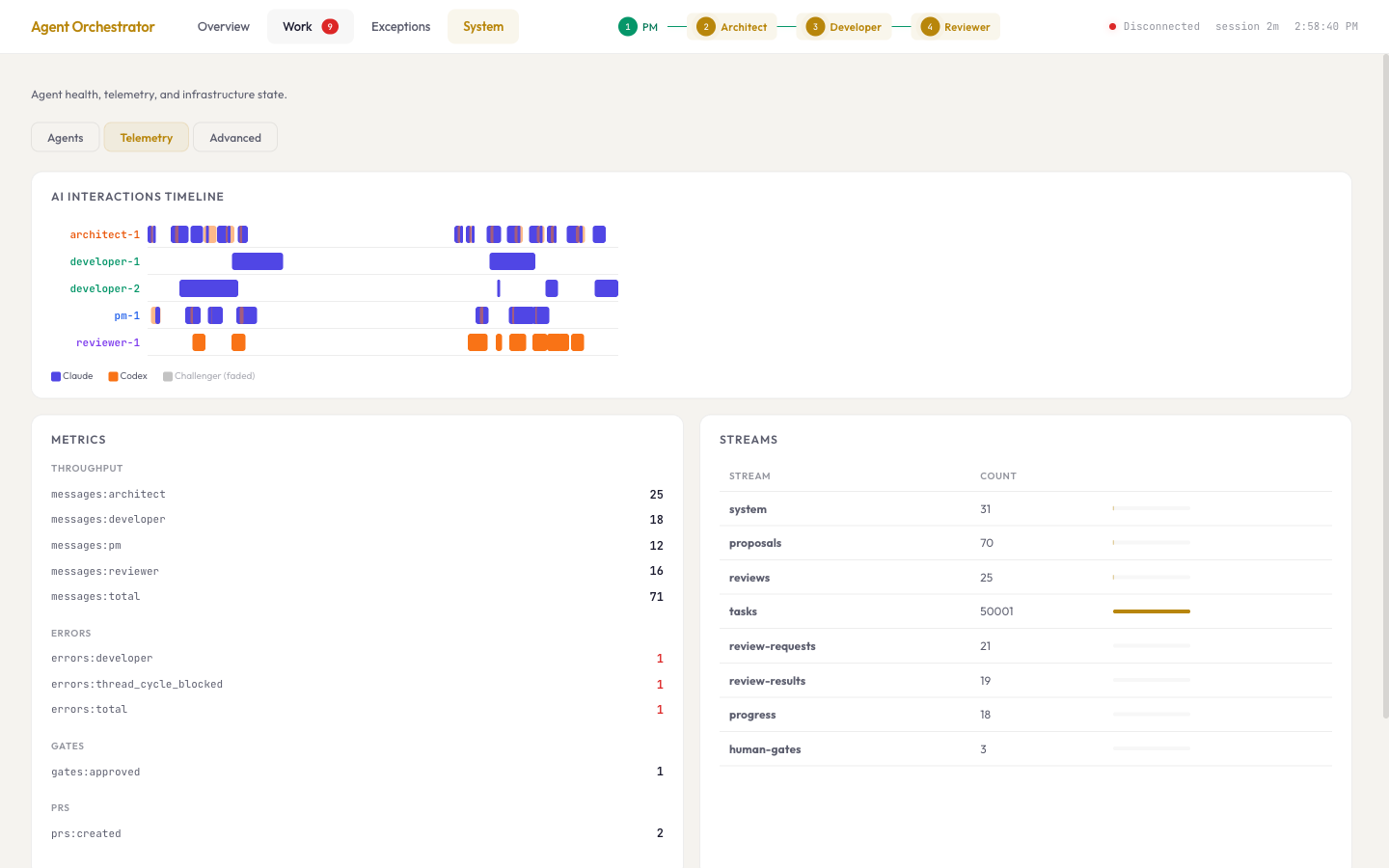
The agents created 24 branches during the week. Four were useful. 83% waste rate. Most people assume AI means efficiency. The reality was high output, low yield. The system generates before it evaluates. Everything enters the pipeline. The pipeline does the filtering.
Some of that waste was avoidable. Better technical guidelines upfront, tighter scoping from the Tech Lead, more specific acceptance criteria would have killed bad branches earlier or prevented them entirely. The PM proposed work that sounded reasonable but wasn't grounded in what the codebase could support. The Tech Lead approved specs that were too broad. The Developer created branches for work already overtaken by changes on main. Each of those is a leadership failure, not an AI failure.
This is where the experiment got personal. The people best positioned to run AI teams right now aren't pure PMs or pure engineers. They're the ones with enough depth across product, engineering, and operations to set the right constraints before the expensive work starts. If you understand the codebase well enough to scope work tightly, you prevent bad branches. If you understand the product well enough to write a real brief, you prevent scattered proposals. If you understand flow well enough to design backpressure, you prevent the pipeline from burning tokens on work it can't finish.
The 83% waste rate wasn't a fact about AI. It was a fact about how much I still had to learn about setting constraints for a team that executes literally.
One pull request made it all the way through, fully autonomous. The system found the opportunity, checked feasibility, wrote the code, reviewed it, and shipped it. No human wrote a line. The human just defined what mattered.
The role that doesn't have a name yet
I came out of this week frustrated that there's no good name for what I was doing.
"AI product management" doesn't cover it. I wasn't just defining requirements. I was building the infrastructure, designing the architecture, operating the system, debugging production issues, and making product judgment calls. All at once.
"AI engineering" is too narrow the other way. The hardest problems weren't technical. They were about what the PM should optimize for, why the pipeline needed a Designer before the Tech Lead, when the system was doing useful work versus generating noise, and whether the dashboard was building trust or just showing data.
The closest word I have is founder. Not because this is a startup. Because the role requires the same combination: you build the thing, you define the vision, you operate it, and you make judgment calls with incomplete information.
During the week I wore four hats, and none of them came off.
I pair-programmed the orchestrator, the dashboard, the safety layer, and the test suite. 360 tests. Four dashboard redesigns. An auditor I built because I got tired of manually checking pipeline health. When I realized the team needed a Designer role, I wrote the prompt, built the agent, and wired it into the pipeline.
I designed the backpressure model, the WIP gates, the thread guard, the message contracts, and the pipeline topology itself. PM to Designer to Tech Lead to Developer to Reviewer, with routing that skips the Designer for purely technical work.
I ran the system live. Diagnosed stalls from Redis state. Paused the PM when the pipeline was full. Abandoned threads that hit capability boundaries.
I defined what each role should care about. Wrote the PM's product brief. Decided the Designer should evaluate trust and experience quality, not decoration. Shaped what the dashboard should show and what to hide.
What prepared me for this wasn't any single skill. Product work taught me to define priorities. Engineering taught me to build observable systems. Running teams taught me when to step in and when to back off. This experiment pulled on all of it at once.
If you're thinking about trying this
Build the window before the engine. I wish I'd started with the dashboard on day one. You can't lead what you can't see.
Write a product brief before you touch any configuration. One page. Three priorities. What's out of scope. That single page shaped the entire week more than any technical decision I made.
Structure beats intelligence. Smart agents with bad handoffs produce waste. Average agents with clear contracts produce value. Design the handoffs first.
Don't let the system start work it can't finish. Those tokens taught me that.
Add craft roles, not just execution roles. The Designer changed the quality of what reached the Tech Lead. On a real team you wouldn't skip design review for user-facing work. Same principle here.
You will be the only one who notices when the direction is wrong. Get comfortable with that.
What I'm taking forward
One thing that struck me during the week was how much the experiment echoed ideas from Team Topologies. Clear boundaries mattered. Cognitive load still mattered. Every extra handoff introduced friction. The supporting layer around the team (orchestration, safety, monitoring, recovery) ended up being just as important as the execution roles.
But it goes deeper than team design. What this week really brought back was engineering fundamentals. Boundaries. Domain models. Building quality in from the start. These things become non-negotiable when critical thinking happens this fast and with this few natural feedback loops. On a human team, bad assumptions get caught in hallway conversations, in code review banter, in the PR comment that says "wait, are we sure about this?" AI teams don't have any of that. If you don't build the feedback loop into the pipeline explicitly, it doesn't exist.
That means the feedback loops need to be left-shifted. Quality gates, scope constraints, design review, all of it has to happen before the expensive work starts, not after. The PM's product brief. The Designer's experience review. The Tech Lead's scoping. Each one is a left-shifted feedback loop that prevents waste downstream.
Does that mean AI teams do waterfall? It might look like it from the outside. PM writes brief, Designer reviews, Tech Lead scopes, Developer implements, Reviewer checks. That's a sequential pipeline. But the loops are short and the iterations are fast. A proposal can get sent back to the PM, revised, and resubmitted in minutes. A review cycle that would take a week on a human team takes hours. The pipeline is sequential at any given moment, but it iterates faster than most agile teams ship. It's not waterfall. It's rapid iteration with explicit phase gates. The structure is heavier than agile. The cycle time is shorter.
That distinction matters for anyone thinking about how to run AI teams. You need more structure than you'd expect, but you get more speed than you'd expect in return. The cost of structure goes down when the team executes in minutes instead of days.
Running an AI team didn't make me feel less needed. It made me feel needed in every direction at once. Builder, system designer, operator, product lead. All of them running in parallel, because the system needs all of them and there's only one human in the room.
Some people will call that "AI PM." I don't think that's quite right. It's closer to founder, just with a different kind of team.
The learning compounds. Frustrations turned into features. Failures turned into things I could actually explain to someone else. Even when the system was broken, I was getting sharper at understanding how teams work and where my own instincts are strongest.
I don't think AI replaces the human in the loop. I think it raises the bar for what the human needs to bring. Not just product thinking. Not just engineering. Both, plus the judgment to know which one matters right now. This week gave me a pretty concrete sense of what that looks like in practice.
I'm a product lover and builder exploring what AI-first teams actually require. I built Agent Orchestrator in two weekends: a multi-agent system where five LLM agents (PM, Product Designer, Tech Lead, Developer, Reviewer) work as an autonomous engineering team on real codebases. Built with Claude Code and Codex, open source if you want to try it. I'm always up for talking to people thinking about the intersection of AI, product, and team design: LinkedIn. This post has been edited and refined with the help of a custom Claude Skill